



Advanced Research Group
ご興味・ご関心ございましたら、こちらから
新着記事
IMAGICA GROUP ARG(Advanced Research Group)とオー・エル・エム・デジタルでは、奈良先端科学技術大学院大学、千葉大学と共同でアニメキャラクター線画に対する自動彩色技術に関する研究を進めています。
ここでは、その成果の1つである、アニメスタイルの自動彩色手法をご紹介します。
まず、我々の自動彩色手法を用いた彩色結果の例を図1に示します。Few-shot learningにもとづき、少数の線画・彩色済みの線画のペアを使ってアニメスタイルの自動彩色を行っています[1]。
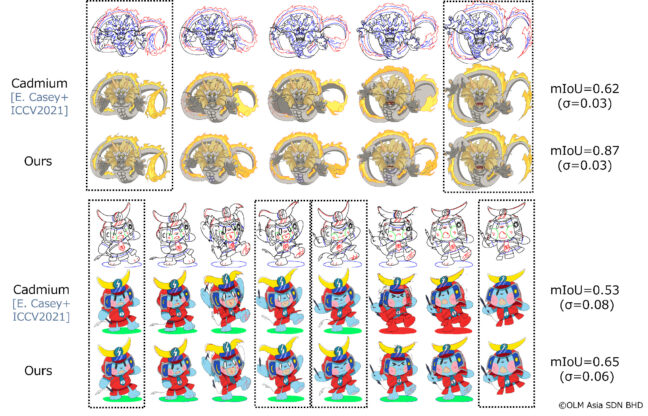
比較のため、ICCV2021で発表されたAnimation Transformer[5]を使った彩色ツールCadmium App[6]を使った彩色結果も示してあります。mIoUとは、領域分割の精度評価で一般的に使われているもので、カッコ内の値は標準偏差を表しています。このmIoUを指標としたとき、手作業による彩色結果と比較して6~7割正しい彩色ができていることが分かりました。
キャラクタ線画に対する彩色は、色見本で指定された色を線画内の対応する領域に塗っていく作業です。今までは、いわゆるバケツ塗りつぶしツール[2]を使って、人手で20〜30枚程度の線画に30分程度の時間をかけて行われてきました。
最近のAI技術の進展により、大量データを用いた白黒映像やイラスト等への自動彩色技術が提案されてきており、我々も大量にデータを確保できるアニメキャラクターの線画に対する自動彩色技術を開発[3]、テストをしてきました。実験レベルでは手作業での彩色と比較しても8割程度の精度で彩色できていたものの、過去に存在しない見た目(表情、服装の変化やアクセサリー等の小物の有無)への対応や、登場頻度の低いキャラクタへの適用が難しいという課題がありました。
一方、実写のビデオ映像に対するスタイル変換技術(入力画像を与えられた見本画像のスタイルへと変換する技術)において、画像を小さなパッチに分割し、スタイル変換前後の同じ位置から得られるパッチの対から局所的なマッピングを学習するパッチベース学習が提案[4] されており、少数の見本画像のみからでもスタイル変換可能なモデルを学習できることが示されました。
我々の手法は、この学習方法をベースにアニメ特有の特徴を考慮し、アニメスタイルの彩色ができるように拡張したものです。
具体的な拡張点は、(1)アニメ特有のべた塗りに対応させる点、(2)線画の特徴を考慮したパッチのサンプリング位置の決定とサイズの決定を導入した点、(3)見た目が似ていても位置によって塗るべき色が異なるパッチに対して、位置情報の埋め込みを導入して周りの色に合わせた塗り方をできるようにした点、です。
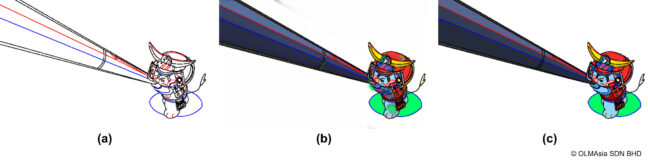
彩色の問題を、線画から彩色済みの線画へ(色から色へ)の回帰問題として考えた場合、AIの出力が連続値となるため、水彩画のようなグラデーションをともなう彩色結果となってしまいます。図2に線画(a)に対する彩色結果(b)、および人手による彩色結果(c)を示します。(b)と(c)を比較すると、特に手の部分に色のにじみがあり、正解には無い色で塗られていることが分かります。アニメの彩色においては、指定された色のみを使って、いわゆるべた塗りと呼ばれる、線で囲まれた領域を単一の色で塗りつぶすことが要求されます。
そこで私たちは彩色の問題を、入力の線画に対して画素ごとに色に対応するラベルを推定する領域分割問題として捉え、アプローチすることにしました。図3を用いて具体的に説明します。まず、線画(a)とラベル画像(c)を用意します。ラベル画像は、人手による彩色結果(b)の色に対してそれぞれIDをラベル付けし色パレット(d)を構築し、色をIDに置き換えることで得られます。線画とラベル画像をともにニューラルネットワーク(以下、NN)に与えることで、NNが画素ごとにラベルを返すように学習させます。彩色は、学習済みのNNに彩色対象の線画(e)を与え、出力されたラベル画像(f)に対して、各閉領域(g)の全ての画素についてその領域の再頻出のラベルに置き換え(h)、最後にラベルを色へと置き換える(i)ことで実現しています。正解である人手による彩色結果(j)と比較して、いくつかの間違いはありますが、指定された色のみを使ったアニメスタイルの彩色ができていることが分かります。

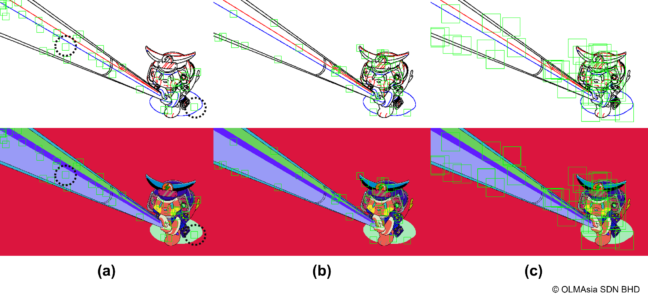
実写画像と比較してアニメキャラクターの線画は画素値の変化が少なく、パッチの大きさとサンプルされる位置によっては、線のまったく存在しない(単一の画素値のみを持つ)パッチがサンプルされる可能性があります。線画のパッチに対応する、彩色済み画像の同じ位置からサンプルされるパッチは、背景もしくは線で囲まれたキャラクタの内部の領域のいずれかを表す((図4. (a)の破線部分))ことになり、あいまいなマッピングを生むため、最終的に学習されたモデルの性能が低下します。これを避けるために、色の境界である輪郭線上の点もしくはそれらの交点を、古典的なコーナー検出を用いて計算し、得られた点群からパッチをサンプルする位置を決定しています(図4. (b))。パッチのサイズは、上で述べたあいまいさを排除し、彩色精度を上げるために十分な大きさにすべきですが、学習時間に影響するためもっともバランスの取れたサイズを採用しています((図4. (c)))。
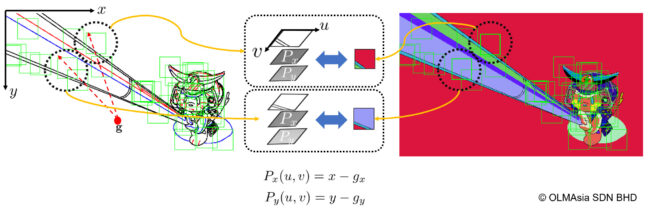
線画によっては、別々の位置からサンプルされたパッチが似たようなパターンを持ち、彩色済み画像のパッチのラベルが異なるという場合が考えられます。これも(2)で述べたあいまいなマッピングを生みます。そこでサンプルされた位置の情報を線画のパッチに埋め込むことで、たとえ見た目が似ていたとしてもその位置の周りの色に合わせた塗り方ができるようにしました(図5)。
学習は、見本として与える画像の枚数が2~4枚の場合、Quadro RTX8000上で概ね3分程度で完了します。学習が短時間で終わるため、作業対象に合わせた彩色モデルをその場で学習させることができるという点がこの方法の利点であると考えています。
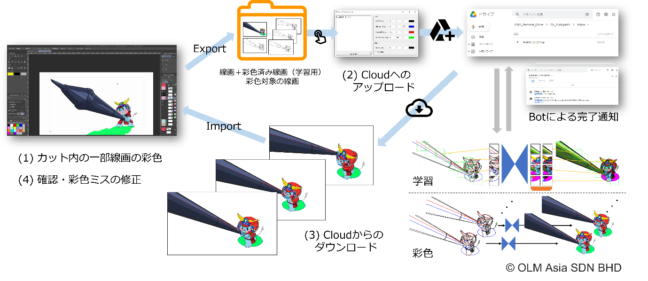 図6.我々の手法を使った彩色ワークフロー
図6.我々の手法を使った彩色ワークフロー
現在、我々の手法をベースとしたワークフロー(図6)をグループ会社であるOLM Asiaにてテストしており、実運用に向けた問題の洗いだしと課題の解決に取り組んでいます。今後は、全体の処理の高速化、既存のツールとの連携強化についても取り組んでいく予定です。
視覚×コミュニケーション×AI
最先端の研究分野で化学反応を起こし、まだ誰も見たことのない映像表現を追求
奈良先端科学技術大学院大学×千葉大学×IMAGICA GROUP
参考文献:
[1] Akinobu Maejima, Hiroyuki Kubo, Seitaro Shinagawa, Takuya Funatomi, Tatsuo Yotsukura, Satoshi Nakamura, and Yasuhiro Mukaigawa. 2021. Anime Character Colorization using Few-shot Learning. In SIGGRAPH Asia 2021 Technical Communications (SA ’21 Technical Communications). Association for Computing Machinery, New York, NY, USA, Article 8, 1–4. https://doi.org/10.1145/3478512.3488604
[2] https://helpx.adobe.com/jp/photoshop/using/tool-techniques/paint-bucket-tool.html
[3] Daichi Ishii, Hiroyuki Kubo, Seitaro Shinagawa, Akinobu Maejima, Takuya Funatomi, Satoshi Nakamura, and Yasuhiro Mukaigawa. 2020. Confidence-Aware Practical Anime-Style Colorization. In ACM SIGGRAPH 2020 Talks(SIGGRAPH ’20). Article 40, 2 pages.
[4] Ondřej Texler, David Futschik, Michal Kučera, Ondřej Jamriška, Šárka Sochorová, Menglei Chai, Sergey Tulyakov, and Daniel Sýkora. 2020. Interactive Video Stylization Using Few-Shot Patch-Based Training. ACM Transactions on Graphics 39, 4 (2020), 73.
[5] Evan Casey, Víctor Pérez and Zhuoru Li, “The Animation Transformer: Visual Correspondence via Segment Matching,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 11303-11312, doi: 10.1109/ICCV48922.2021.01113.
映像表現の最先端で一緒に働きませんか?
研究開発に興味をお持ちの方、
実現したい何かをもつ方、映像分野が好きな方はぜひご応募ください。
誰も見たことのない未来をともに創り出すメンバーを待っています。

▶︎IMAGICA GROUP アドバンストリサーチグループ 採用情報はこちら
